Make subtitles for each audio using whisper
Surely you know about openai/whisper
or if not go read about it.
in short: it is a tool to transcribe text from audio.
Does not matter how good your GPU is, it takes forever to generate subs for 90G of audio.
Thats where faster-whisper enters the stage.
It might be 4x times faster as original whisper without losing accuracy! (but sometimes introducing new bugs though);
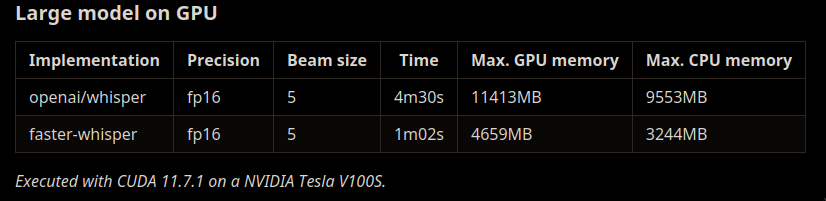
This is no handholding | spoonfeeding article. It is more about sharing my experience than providing a tutorial. Also in these dynamic times the more specific you get, less valuable you become when something change.
- install whisper;
- download medium model (not medium.en, we're targeting german);
- download faster whisper repo;
- pip install inside of virtualenv (there is two requirements files, use both if stuck);
ct2-transformers-converter --model openai/whisper-medium --output_dir whisper-medium-ct2 --quantization float16
- write a python script to transcribe files (I'll share mine);
Transcribe script (mostly inspired by original)
from faster_whisper import WhisperModel
model_path = "/home/grail/projects/third_party/faster-whisper/whisper-medium-ct2"
# Run on GPU with FP16
model = WhisperModel(model_path, device="cuda", compute_type="float16")
def format_timestamp(seconds, always_include_hours=False, decimal_marker="."):
assert seconds >= 0, "non-negative timestamp expected"
milliseconds = round(seconds * 1000.0)
hours = milliseconds // 3_600_000
milliseconds -= hours * 3_600_000
minutes = milliseconds // 60_000
milliseconds -= minutes * 60_000
seconds = milliseconds // 1_000
milliseconds -= seconds * 1_000
hours_marker = f"{hours:02d}:" if always_include_hours or hours > 0 else ""
return f"{hours_marker}{minutes:02d}:{seconds:02d}{decimal_marker}{milliseconds:03d}"
def write_result(file, segments):
print("WEBVTT\n", file=file)
for segment in segments:
print(
f"{format_timestamp(segment.start)} --> {format_timestamp(segment.end)}\n"
f"{segment.text.strip().replace('-->', '->')}\n",
file=file, flush=True,
)
print(
f"{format_timestamp(segment.start)} --> {format_timestamp(segment.end)}\n"
f"{segment.text.strip().replace('-->', '->')}\n",
)
if __name__ == "__main__":
import sys
import os.path
filepath = sys.argv[1]
vtt_out = filepath + ".vtt"
if os.path.isfile(vtt_out):
print(vtt_out, "already exists")
exit(0)
segments, _ = model.transcribe(filepath, beam_size=5, language="de")
with open(vtt_out, "w") as lf:
write_result(lf, segments)
Script will take path to audio file (downloaded from youtube it mostly opus and m4a)
and shall (if no mistakes) create output file with same name as original (including extension) plus .vtt
vtt_out = filepath + ".vtt"In future we will depend on this naming convention: that you can take .vtt file, remove .vtt extension and get original audio file.
Now with that script all you need to do is run something like
for f in /path/to/audios; do python fw_transcribe.py "$f"; done
and wait a few days (and nights). Should be less than a week.
Conclusion and next page
- you learned about faster whisper
- you extracted subs for 90G audio (after less than a week of gpu run)