Cleaning part (dealing with duplicates and gibberish)
Patterns of the problems
- The first and last lines of the frame are usually the most damaged ones, often because they partially hidden by top/down border;
- end lines of a page gets repeated by beginning lines of the following page.
End of the first page
widerstehen, die die Hügel östlich des Heiligen Königreichs zwischen ihnen und
der Theokratie besetzten.
Diese großartige Mauer, die mit viel Zeit und Ressourcen errichtet wurde, war
ein stilles Zeugnis dafür, wie beunruhigend die Existenz der Demihümän für das
Heilige Königreich war
Es gab eine große Machtlücke zwischen Demihümän und Menschen.
Zugegeben, es stinmte, dass es bestimnte Demihümän gab, die schwächer waren als
L_uanschen _ wie zum Baisniel Gahlins ——
Start of the second page
widerstehen, die die Hügel östIıch des Heilıgen Könıgreichs zwischen ıhnen und
der Theokratie besetzten.
Diese großartige Mauer, die mit viel Zeit und Ressourcen errichtet wurde, war
ein stilles Zeugnis dafür, wie beunruhigend die Existenz der Demihümän für das
Heilige Königreich war.
Es gab eine große Machtlücke zwischen Demihümän und Menschen.
Zugegeben, es stimte, dass es bestimnte Demihümän gab, die schwächer waren als
Menschen, wie zum Beispiel Gob!
Plan to solve these issues
- If lines contains too many non words (dictionary check), it is a failed line => delete that line;
- If line has a fuzzy duplicate in prev page (same line can be extracted with a few symbol difference) => discard that line;
Enchant and cleaning script in python
Enchant is a spellchecker
that happened to be one that I found while searching for it;
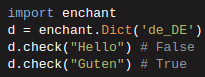
enchant installation isn't straightforward, I recommend you check installation guide
$ pacman -Q | grep enchant
enchant 2.3.1-2 python-pyenchant 3.2.1-1
looking for gibberish (unreadable lines)
The idea is to check every word in line; if this word belongs to the dictionary. By dividing dictionary words on total words in line one gets the sanity index of the line. When sanity index of the line is too low (deduced by practice: less than .8), that line should be branded as gibberish and discarded.
def gibberish_ratio(line):
words = line.split(" ")
# list of bool: [True, False, True...]
sane = [ge_dict.check(w) for w in words if w != ""]
return sum(sane) / len(sane)
The cleaning script by plan: remove_dups.py
./remove_dups.py text result/v12_clean.txt
new files appear: skipped_gibberish and v12_clean.txt
Remaining issues
- title line: Der Dämonenkaiser Yaldabaoth l got filtered, because only Der Dämonenkaiser returns True on the spellcheck;
- there is still numerous new lines in between pages (which I don't mind so I left them be);
- there are ways to play around with image quality, font-size, passind dpi as an argument to tesseract, etc;