I wanted to read Overlord v12 in german and was not able to find it in the text format so I had to use ffmpeg/imagemagick/tesseract to extract the text from video
There are the first three volumes translated by a fan and have theirs existence in pdf forms, which is nice. But I don't find most of the volumes worth reading except for volumes 12 (mainly) and 13 (some parts) which have new superior character and were noticeably inspired by melian dialogue.
Surprisingly a youtube video exists,
that presents itself to be an audiobook read by some text-to-speech software. Important thing is: text itself is displayed.
Before we do anything: asking uploader to share text won't hurt
(which is not true; hearing a no always hurts)
Dependencies on article writing moment:
pacman -Q | grep "tesseract\|ffmpeg\|magick\|python 3" ffmpeg 2:4.4.1-1 imagemagick 7.1.0.16-1 python 3.9.9-1 tesseract 4.1.1-8 tesseract-data-deu 2:4.1.0-1 tesseract-data-eng 2:4.1.0-1
Now the plan is:
- Download the video
- Take screenshot/frame for every new page
- Make frame more readable by ocr/tesseract
- Use tesseract to each frame
- Clear from duplicates and nonsense
- Merge text into one file
- Read it
Before downloading the whole video lets do quick proof of concept with one frame
ffmpeg -i $(yt-dlp -f best --get-url "https://www.youtube.com/watch?v=WQvrbZEK0LE") -ss 00:00:02 -vframes 1 poc.jpg
or you can use youtube-dl, if for some reason you want to
ffmpeg -i $(youtube-dl -f best --get-url "https://www.youtube.com/watch?v=WQvrbZEK0LE") -ss 00:00:02 -vframes 1 poc.jpg
- -i {{source}} points to the source of the stream
- -ss 00:00:02 starting from second second
- -vframe 1 just take one frame
- poc.jpg output file
Now lets try some lazy extraction
tesseract -l deu poc.jpg poc
Tesseract Open Source OCR Engine v4.1.1 with Leptonica
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 127
Error in boxClipToRectangle: box outside rectangle
Error in pixScanForForeground: invalid box
Error in boxClipToRectangle: box outside rectangle
Error in pixScanForForeground: invalid box
A lot of complains, mostly because poc.jpg contains many unnecessary details, not the best dpi, font size, etc; here is the list of suggestions on improving extraction result (we'll use some of them)
Image source
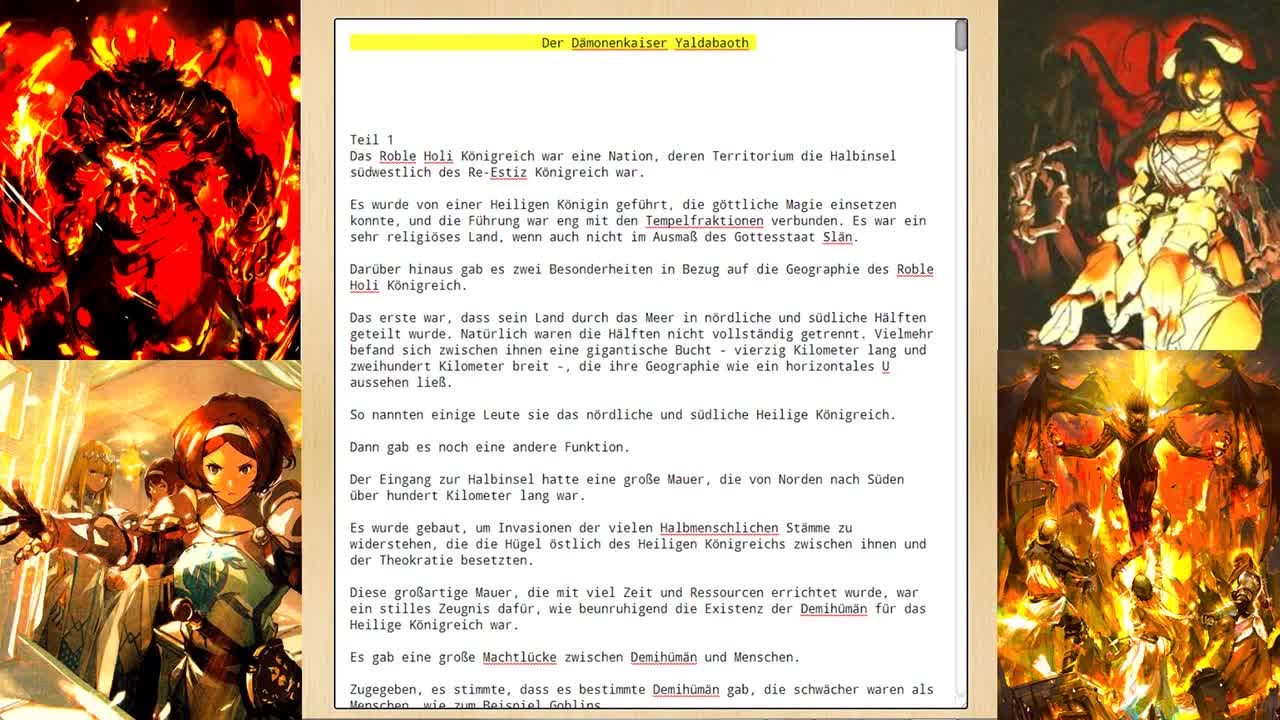
Text output
Teil 1
Das Roble Holi Königreich war eine Nation, deren Territorium die Halbinsel
südwestlich des Re-Estiz Königreich war
Es wurde von einer Heiligen Königin geführt, die göttliche Magie einsetzen
konnte, und die Führung war eng mit den Tempelfraktionen verbunden. Es war ein
sehr religiöses Land, wenn auch nicht im Ausmaß des Gottesstaat Slän
Darüber hinaus gab es zwei Besonderheiten in Bezug auf die Geographie des Roble
Holi Königreich
Das erste war, dass sein Land durch das Meer in nördliche und südliche Hälften
geteilt wurde. Natürlich waren die Hälften nicht vollständig getrennt. Vielmehr
befand sich zwischen ihnen eine gigantische Bucht - vierzig Kilometer lang und
zweihundert Kilometer breit -, die ihre Geographie wie ein horizontales U
aussehen ließ.
So nannten einige Leute sie das nördliche und südliche Heilige Königreich.
Dann gab es noch eine andere Funktion.
Der Eingang zur Halbinsel hatte eine große Mauer, die von Norden nach Süden
über hundert Kilometer lang war.
Es wurde gebaut, um Invasionen der vielen Halbmenschlichen Stämme zu
widerstehen, die die Hügel östlich des Heiligen Königreichs zwischen ihnen und
der Theokratie besetzten.
Diese großartige Mauer, die mit viel Zeit und Ressourcen errichtet wurde, war
ein stilles Zeugnis dafür, wie beunruhigend die Existenz der Demihümän für das
Heilige Königreich war
Es gab eine große Machtlücke zwischen Demihümän und Menschen,
Zugegeben, es stimte, dass es bestimnte Demihümän gab, die schwächer waren als
L_itanschen wi Baisniel Gahl
Summary of what happened (if you followed this article)
You have run two commands and got the image frame and the text file;
Now you feel determined to continue reading (probably)
ffmpeg -i $(yt-dlp -f best --get-url "https://www.youtube.com/watch?v=WQvrbZEK0LE") -ss 00:00:02 -vframes 1 poc.jpg
tesseract -l deu poc.jpg poc
In the next article: how to get better text output and make extracting this better output from every page on the video